Monday AI Radar #25
Can the metrics keep up with the models?
We’re racing toward AGI, but at least we have good metrics to guide us, right?
METR’s Time Horizon 1.1 is saturating, and we don’t have a clear replacement. While Claude is making rapid progress on Anthropic’s current misalignment assessments, those assessments won’t be sufficient for AGI. All is not lost: we have two pieces from Epoch discussing strategies for future benchmarks, and a promising new benchmark for assessing whether AI is a good influence on people. Beyond formal evaluations, Andon Labs reports on a (partly successful) experiment in having AI run a coffee shop.
Top pick
Teaching Claude why
What’s behind Claude’s recent rapid progress on Anthropic’s misalignment assessments? Anthropic shares some new findings—the headline is that they’re getting good results from training Claude to reason about moral principles and its constitution.
They find that training against a particular bad behavior (like blackmail) is effective at reducing that behavior, but does not generalize well to other forms of misalignment. On the other hand, training on moral principles generalizes well to a range of different situations. Moral reasoning specifically is important: merely using examples of good behavior isn’t sufficient. These results are further evidence that Anthropic’s approach to alignment is working well, at least at current capability levels.
There’s another interesting finding buried in the article: they believe the misaligned behaviors they were investigating originated primarily in pre-training rather than misaligned rewards during post-training. That’s encouraging since failures during RL are considered a likely source of future catastrophic misalignment.
Related: Zvi collects some recent Twitter discussions about how Anthropic sees Claude and itself.
Forecasts
Is AI 2027 Coming True?
Steve Newman asks whether recent progress is keeping pace with the AI-2027 scenario, exploring three perspectives:
- Dismissive: AI is mostly hype
- Explosive: we’re headed for recursive self-improvement and a fast takeoff
- It’s complicated: AI will ultimately be transformative, but it’ll take decades
The dismissive perspective is obviously wrong, so he focuses on how to tell whether we’re on an explosive trajectory or an “it’s complicated” one:
It’s under-appreciated that the explosive and it’s-complicated views do not diverge much in their predictions until the advent of “strong AGI”.
Steve suggests five leading indicators to watch:
- Do we achieve full automation of AI R&D?
- How long can we benefit from new data center construction?
- Is automated AI R&D enough for rapid progress in all domains?
- Will AI be good enough to diffuse rapidly throughout the economy?
- How quickly do robots get good enough to be broadly useful?
It’s characteristically strong work, though if we get to recursive self-improvement, the answer to all the other questions quickly becomes “yes”.
Three views on the future of work
In a similar vein, Teddy Tawil at Carnegie Endowment identifies three schools of thought on how AI will impact the job market:
- The excited believe human job prospects will improve
- The patient think that whatever happens will take decades
- The alarmed worry about large-scale white-collar job losses over the next decade
All those disagreements, he argues, can be distilled into two core disputes:
- How quickly will AI gain capability and diffuse into the economy?
- To what extent will AI create new jobs?
The employment data remain ambiguous, which is consistent with all three schools of thought. That’s likely to continue until right before we see substantial changes in the data. If we start preparing for job impacts when we know for certain what they’ll look like, it’ll be far too late.
Benchmarks
Task-Completion Time Horizons of Frontier AI Models
METR estimates that Claude Mythos Preview has a time horizon of at least 16 hours at a 50% success rate.
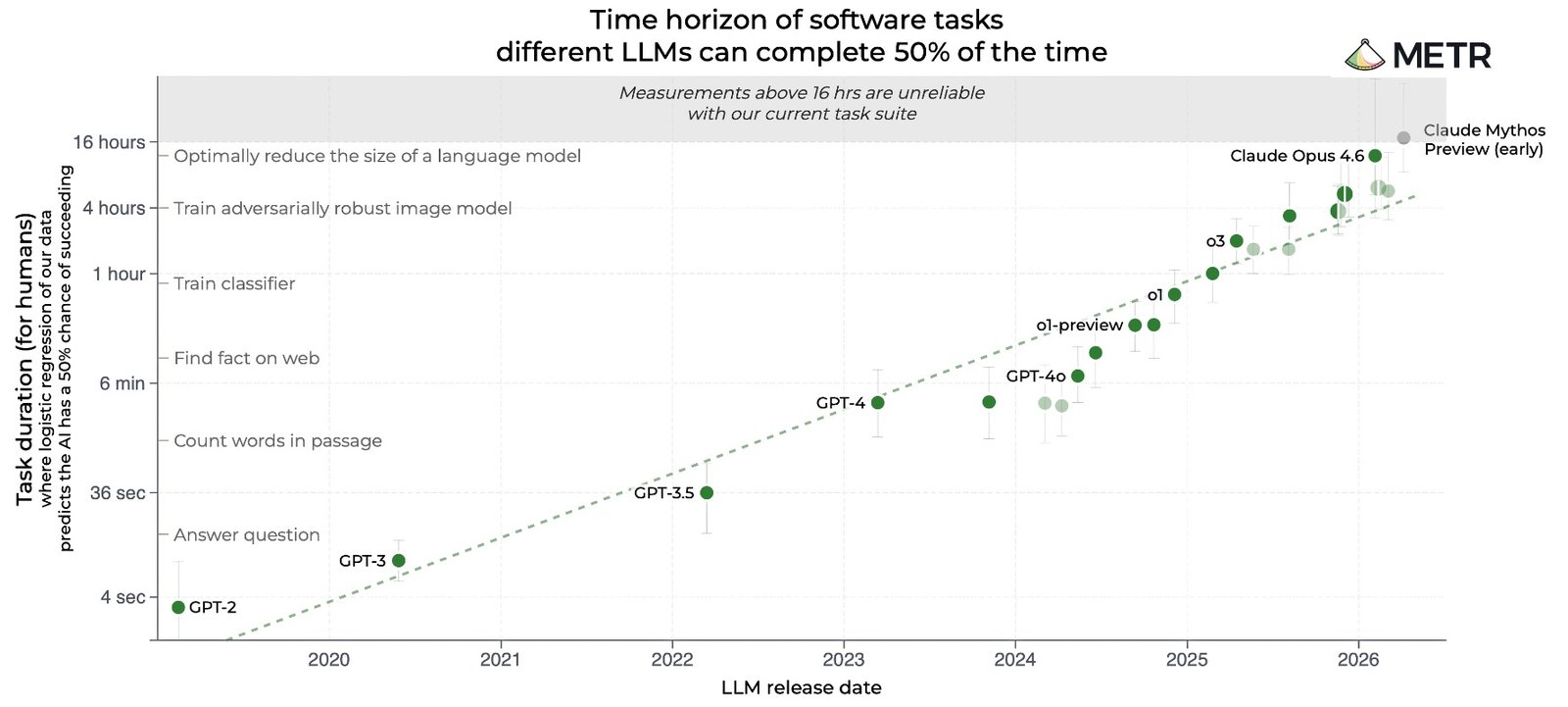
Time Horizon 1.1 cannot reliably measure time horizons beyond 16 hours, so the 50% success version of the benchmark is on the verge of saturation. Even on the 80% success version, Mythos comes in at 3 hours and 6 minutes—at current doubling rates, that might also saturate before the end of the year.
I’m hopeful that METR will find ways to measure longer time horizons. If not, the Epoch Capabilities Index (ECI) is the most obvious replacement candidate for “most useful chart in AI”.
Our AI started a cafe in Stockholm
Hot on the heels of their recent AI-managed storefront in SF, Andon Labs has opened an AI-managed cafe in Stockholm.
This is an expensive but useful type of experiment: managing a store requires navigating real-world chaos in a way that’s hard to duplicate in a benchmark. For now the AIs do surprisingly well, but are not yet close to human performance. These experiments are on my list of likely leading indicators for significant job displacement.
Are AI benchmarks doomed?
We’re facing a minor benchmark crisis: many of our best benchmarks are close to saturation, and frontier models are good enough that it’s increasingly difficult and expensive to create replacements. Epoch brings us two explorations of what might come next.
Greg Burnham suggests we can still create useful benchmarks by giving up any one of four attributes of current benchmarks:
- Text-only,
- Easy to grade,
- Have short time horizons, and
- Solvable by human experts
Tom Adamczewski, Greg Burnham, and Anson Ho are optimistic about the feasibility of creating new AI benchmarks. They explore a variety of solutions including benchmarks that scale easily (like MirrorCode), “bite-sized benchmarks”, and benchmarks that are expensive but valuable enough to be economically viable.
I expect we’ll continue to have useful benchmarks but they’ll look quite different from current benchmarks, just as Time Horizon looks different from GPQA.
Alignment and interpretability
Yoshua Bengio’s Scientist AI
80,000 Hours’ Rob Wiblin talks with Yoshua Bengio about his Scientist AI concept:
a mind that has internalized the laws of nature and uses them to make predictions, but without predilection about how things unfold. It is a highly intelligent machine that uses probabilistic reasoning to understand the world, but with no hidden goals or preferences. Its predictions are transparent, auditable and verifiable.
This seems like a long shot, but worth pursuing. Smart money says current LLM technology can probably go all the way to superintelligence, but that’s not guaranteed. We are under-investing in alternative approaches like Scientist AI.
Cybersecurity
How good is Mythos?
Point Estimate asks whether Mythos is a big leap forward in capability, or roughly on trend, including for cyber capabilities. They tentatively conclude that Mythos is probably one to two months ahead of the trendline but does not represent a major discontinuity (but see below).
Hardening Firefox with Claude Mythos Preview
Mozilla provides further evidence that Mythos is a big deal:
Just a few months ago, AI-generated security bug reports to open source projects were mostly known for being unwanted slop. […]
It is difficult to overstate how much this dynamic changed for us over a few short months. This was due to a combination of two main factors. First, the models got a lot more capable. Second, we dramatically improved our techniques for harnessing these models — steering them, scaling them, and stacking them to generate large amounts of signal and filter out the noise.
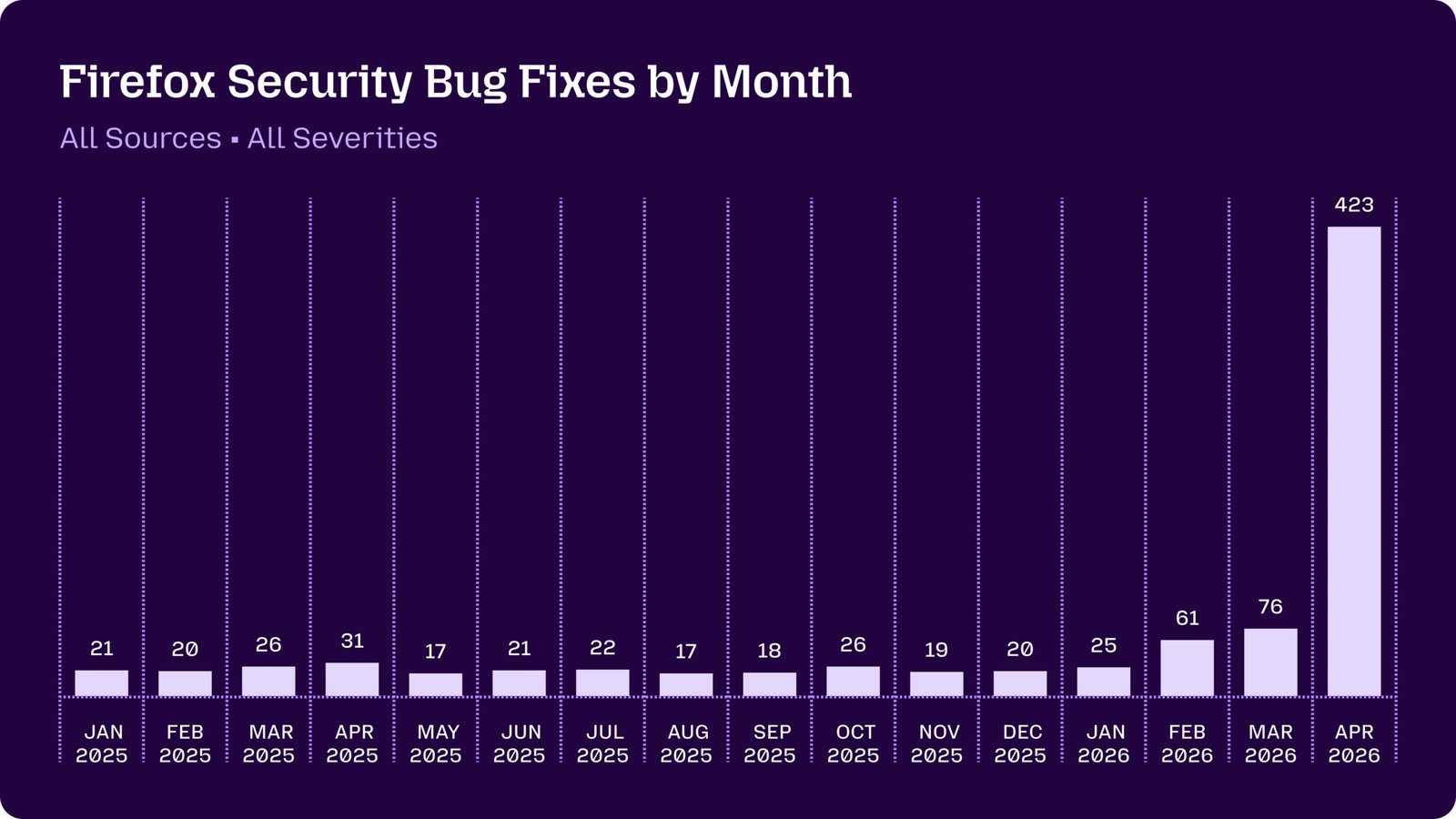
Seemingly high-quality analyses keep coming to different conclusions about Mythos’ cybersecurity capabilities. My best guess is that it’s modestly ahead of the trendline on raw capabilities, but is also the first model to cross a critical capability threshold for real-world impact. If that’s the case, we should soon see reports of other models generating large numbers of high-value vulnerabilities on major projects.
Strategy and politics
AI is changing our minds. When is that a good thing?
We know that AI can change people’s opinions, but how can we tell if it’s having a positive influence? Writing for Cosmos Institute, Maximilian Kroner Dale, Paul de Font-Reaulx, and Luke Hewitt propose a clever metric based on deliberative polling.
Deliberative polling brings together a group of citizens to deliberate on a specific topic. They are given a high-quality briefing and access to an expert who can answer questions about the topic, before deliberating in groups. At the end of the process, they are polled on their opinions. Deliberative polling is widely considered to generate better policy recommendations, while remaining true to the citizens’ values and goals.
DeliberationBench measures whether an AI influences a user’s opinions on a topic in the same direction as deliberative polling. They find that several frontier AIs do indeed move users’ opinions in the same direction as deliberative polling, which is an encouraging sign (although it does not reduce partisan polarization the way deliberative polling does).
The value of deliberative polling is supported by many years of data: using it as a baseline for positive influence is a smart move. I’d love to see more work in this direction.
The AI ad-hoc prior restraint era begins
Zvi contemplates the possibility that the White House might impose some kind of prior restraint on new model releases. Pre-deployment vetting would be great—capricious political interference would be actively harmful. This is exactly correct:
If implemented well, this could be the right thing.
By default, it won’t be implemented well.
A voluntary path to pre-deployment AI vetting
Dean Ball and Kevin Frazier explore options for pre-deployment vetting of frontier models. They conclude there is no clear legal basis for the White House to mandate vetting, but argue that the Center for AI Standards and Innovation (CAISI) is well-suited to administering a voluntary vetting system.
Voluntary vetting is likely the best-achievable option in the short run: it would be immediately beneficial and would provide a good framework for more extensive vetting and regulation in future. It has the further advantage of being less capricious and more predictable than ad-hoc vetting by the executive branch would be.
China
Notes from inside China's AI labs
Nathan Lambert reports back from his visit to China. Culture, as they say, eats strategy for breakfast—it’s rare and valuable to get a peek inside the culture of the big Chinese labs.
Two of his observations fit my previous understanding:
- Export controls are a big deal: “Nvidia compute is the gold-standard for training and everyone is limited in progress by not having more of it.”
- The Chinese educational system and the incentives at the labs are better suited to fast-following the frontier than generating major breakthroughs.
And two of them I wasn’t expecting:
- Chinese researchers have significantly less ego than their US counterparts, and this has meaningful implications for organizational structure.
- The culture is significantly more collaborative: “In China, the LLM community feels far more like an ecosystem than battling tribes. Across many off the record conversations, it’s nothing but respect for peers.”
How to buy cheap Claude tokens in China
Claude is popular in China, which is strange since both Anthropic and the Chinese government prohibit its use there. What’s going on?
ChinaTalk has a fascinating article about the extensive and sophisticated ecosystem of “transfer stations” that illicitly resell Claude inside China. The system is capable and resilient, but full of all kinds of creative fraud.
It’s a fun read and a good case study in the difficulty of imposing top-down control on an online service.
Briefly
Outsourcing to AI
you can outsource your thinking but you cannot outsource your understanding
Correct, no notes.
Task substitution and uplift
METR offers an elegant way of thinking about how AI will increase real-world productivity:
uplift on old tasks <= uplift in value <= uplift on new tasks
Genesis AI robotics demo video
Impressive. Demos always show a skewed version of what a product is actually capable of. More interesting than the content of any specific demo is the rate of progress between demos: like AI, robots are improving quickly.