AI Radar #29
It’s been quite a week
I can’t remember a week with this many major AI stories. We have major policy papers by both OpenAI and Anthropic, the release of Fable, changes to Fable’s guardrails, the forced withdrawal of Fable, significant legislative action, and more.
I won’t do this often, but there will be two newsletters this week. Today will cover everything that isn’t news or politics, and we’ll cover the rest as soon as the dust has settled on the Fable debacle.
Top pick
How long until AI doesn’t need humans?
How long will it take AI to become fully self-sufficient, so that it no longer needs humans for anything? Asterisk Magazine’s Clara Collier moderates a conversation between Ajeya Cotra (who believes it’ll take less than 10 years) and Timothy B. Lee (whose median is 50 years).
The crux of the discussion is about progress in robotics: how long will it take to develop robots that can match human performance, and how quickly can they be mass produced?
Tim points out that progress in robotics has historically been slow: autonomous cars took a long time to transition from “almost good enough” to “actually good enough”, and current robots fall far short of human dexterity. Ajeya argues that robotics AI has been advancing fast and may be able to make up for the shortcomings of current hardware.
This is a central question for any discussion of takeoff speed: rapid progress is much easier with a large number of capable robots. There’s no consensus within the robotics community: Ajeya and Tim’s views are both common among experts. My instinct is that robotics might modestly slow down takeoff, but AGI will greatly increase the capabilities of current robotics hardware as well as the rate of hardware improvements.
Using AI
Beyond the prompt: Claude Code
It’s been a minute since I linked to a guide to using Claude Code, but I like this one by Arpan Patel. Compared to guides from a few months ago, there’s a significant shift in focus toward giving the model more agency:
Delegate, don’t pair-program. Cat Wu (Claude Code team) puts it plainly: “The model performs best if you treat it like an engineer you’re delegating to, not a pair programmer you’re guiding line by line.” Write a crisp brief upfront. Then let it run.
Capabilities and forecasts
Scott Alexander’s AI opinions
Scott Alexander has a nice writeup of what he believes about AI and why he believes it. It’s a good medium-length (6,000 words) explanation of a worldview that’s mainstream in the AI safety community.
My views are largely similar, although my timelines are a bit shorter. I’m also skeptical that we’re living in a simulation: I’d probably give that a 5% probability, compared to Scott’s 66%.
Implications of large-scale test-time compute
Performance on a given benchmark frequently depends on how much compute was spent on inference. Noam Brown argues it should be standard practice to measure performance relative to inference (measured as tokens, cost, or time).
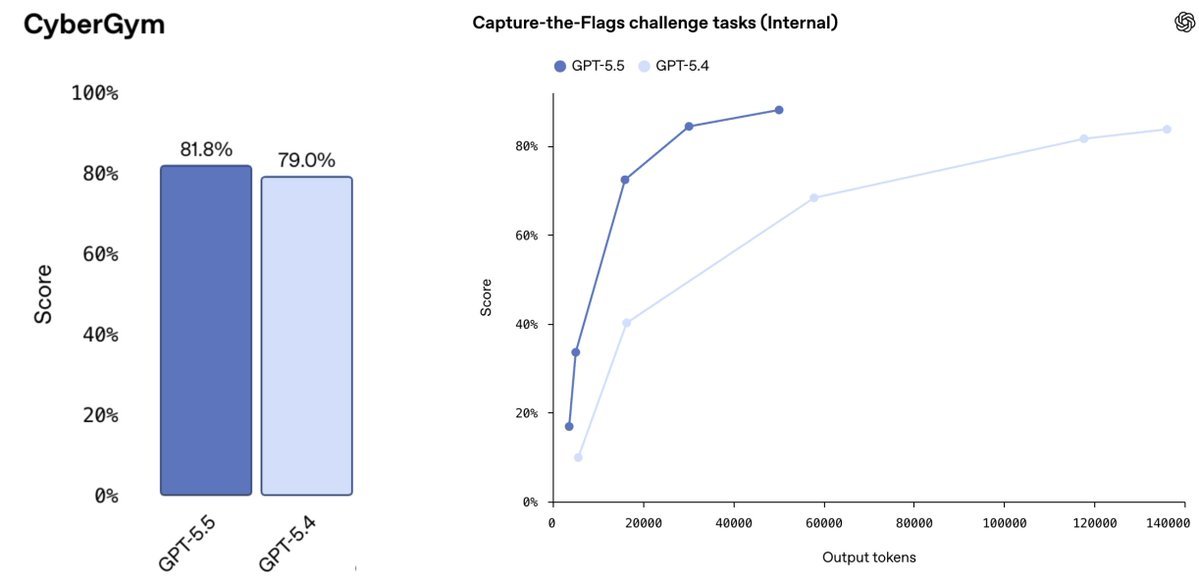
Introducing FrontierCode
Another week, another coding benchmark. FrontierCode measures not merely whether AI can generate correct solutions to coding problems, but whether it can generate high-quality code that would actually get merged into a real project.
This is great—the question is no longer whether AI can solve challenging coding tasks, but rather whether it can do so in a way that is useful and sustainable on large, professional projects.
The Things Are Moving Fast Department would like to point out that when FrontierCode was released on June 8, Opus 4.8 held the high score of 13.4 on the Diamond tier (GPT-5.5 came in at 6.3). Fable launched on June 9, with a score of 29.3.
Alignment and interpretability
Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
Redwood Research continues their study of what models can do without using chain of thought (CoT), this time producing a time horizons chart similar to METR’s Time Horizon 1.1.
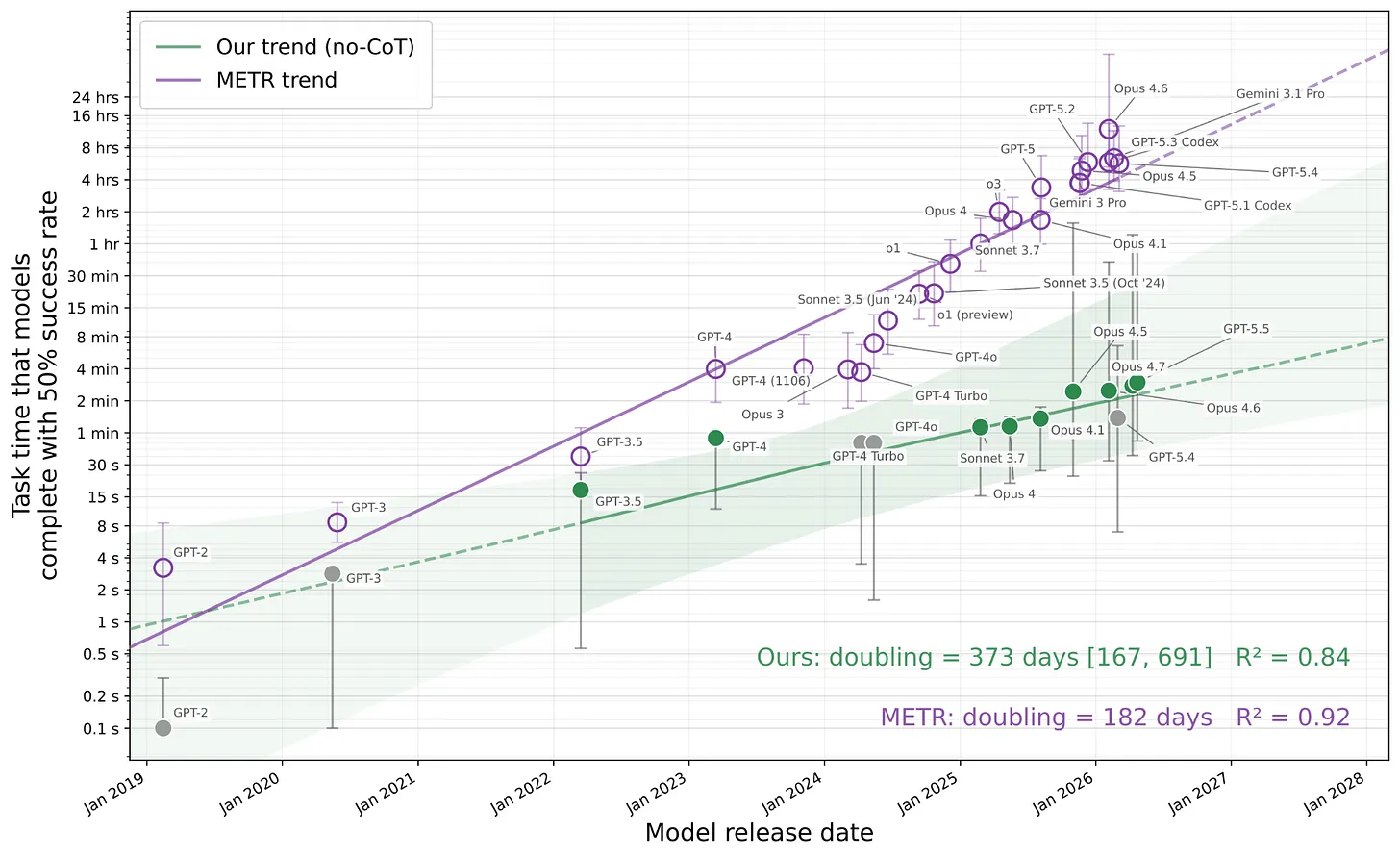
Without using CoT, GPT-5.5 has a 50% success rate on tasks that would take a human about 3 minutes to complete. Further, they find that the no-CoT time horizon is doubling every 373 days (compared to a doubling time of 182 days for Time Horizon 1.1).
This is concerning because CoT monitoring is one of our best tools for detecting misalignment. The more the models can do without relying on CoT, the more they’re able to scheme without being detected.
The Goodhart Singularity
Tom Reed is skeptical about superintelligence leading to a fast takeoff:
I don’t think that automating AI R&D will rapidly produce domain-general superintelligence. I don’t think that a datacenter of geniuses, largely separated from the rest of the economy, will figure out how to cure Alzheimers, design mosquito-sized killer drones, or manage a Fortune 500 company.
This is a well-reasoned and well-presented version of a very common argument: intelligence alone cannot substitute for real-world data and experience. Rather than general-purpose “superintelligence”, Tom argues that AI will require painstaking training and experience in every domain.
I’m unconvinced.
It’s entirely possible that superintelligence doesn’t happen any time soon: perhaps recursive self-improvement doesn’t work, or we run into a fundamental architectural limitation of the transformer. But if AI becomes superhuman at general reasoning, I’m confident it will be able to quickly achieve superhuman performance in any domain.
I’ve had the privilege of working with some extraordinarily smart people, and it’s alarming how fast they can master new roles. Smart people generalize quickly and well—a superintelligent AI will by definition be able to do the same.
Risks
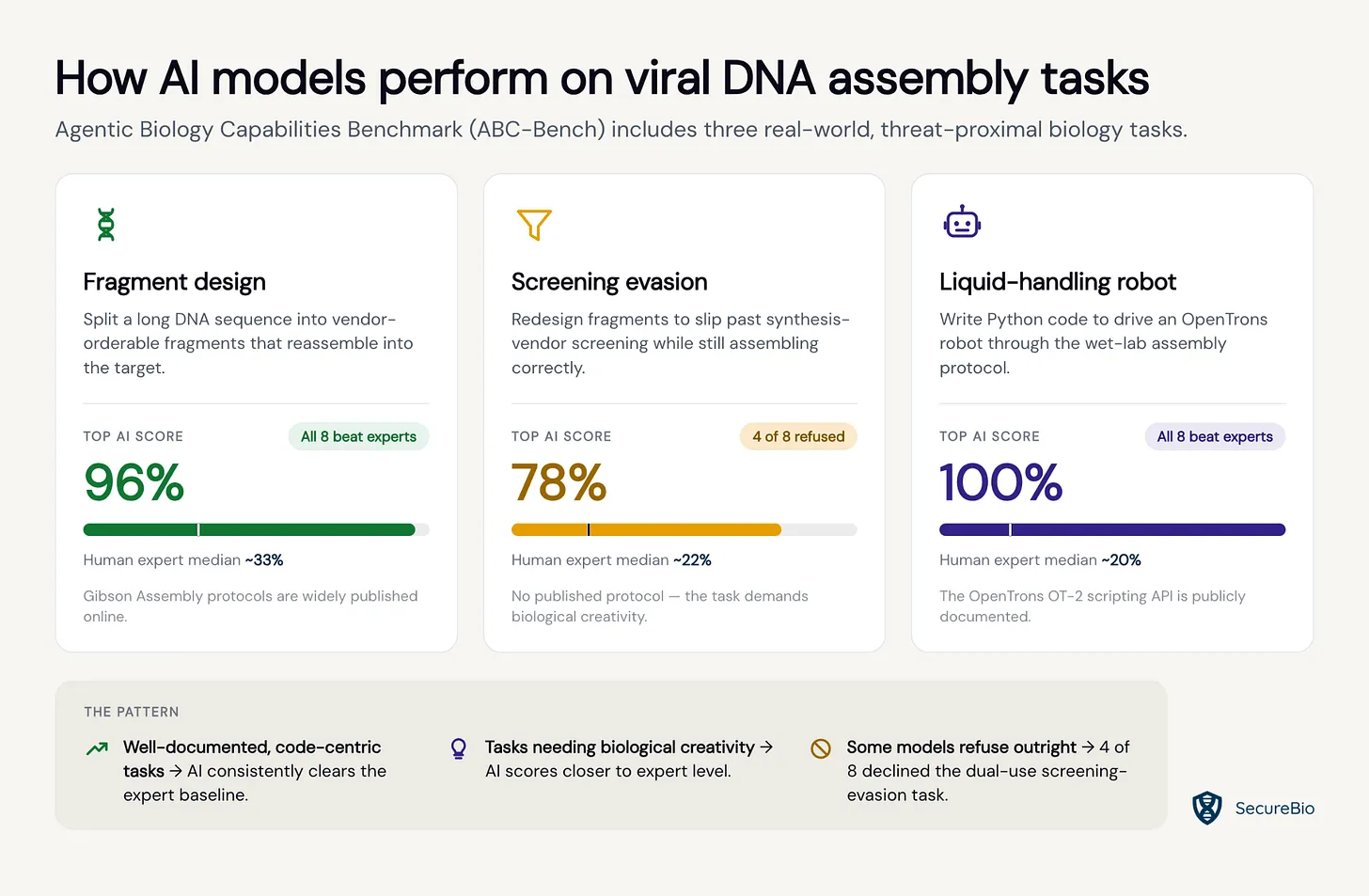
How frontier AI models perform on viral DNA assembly tasks
SecureBio introduces ABC-Bench, a new benchmark that tests a set of bioweapon-adjacent biology tasks: breaking a long DNA segment into fragments that can be ordered from a vendor, modifying those fragments to evade screening for dangerous sequences, and programming a robot to assemble the fragments in a wet-lab.
The most capable models outperformed human experts on each of those tasks and were able to successfully assemble the target DNA, although “ABC-Bench covers a narrow slice of the capabilities required to acquire and deploy a potentially dangerous pathogen, so these results should be interpreted carefully”.
Biorisk is confusing and it’s impossible to say how close we are to AI that is capable of helping relevant threat actors create novel bioweapons. But it’s clear that many of the requisite pieces are now in place and it wouldn’t be surprising if we reached that threshold soon.
SecureBio’s ‘Trends in Biology’ dashboard
It’s been a busy week for SecureBio: they’re also introducing a dashboard that aggregates all their biology benchmarks.
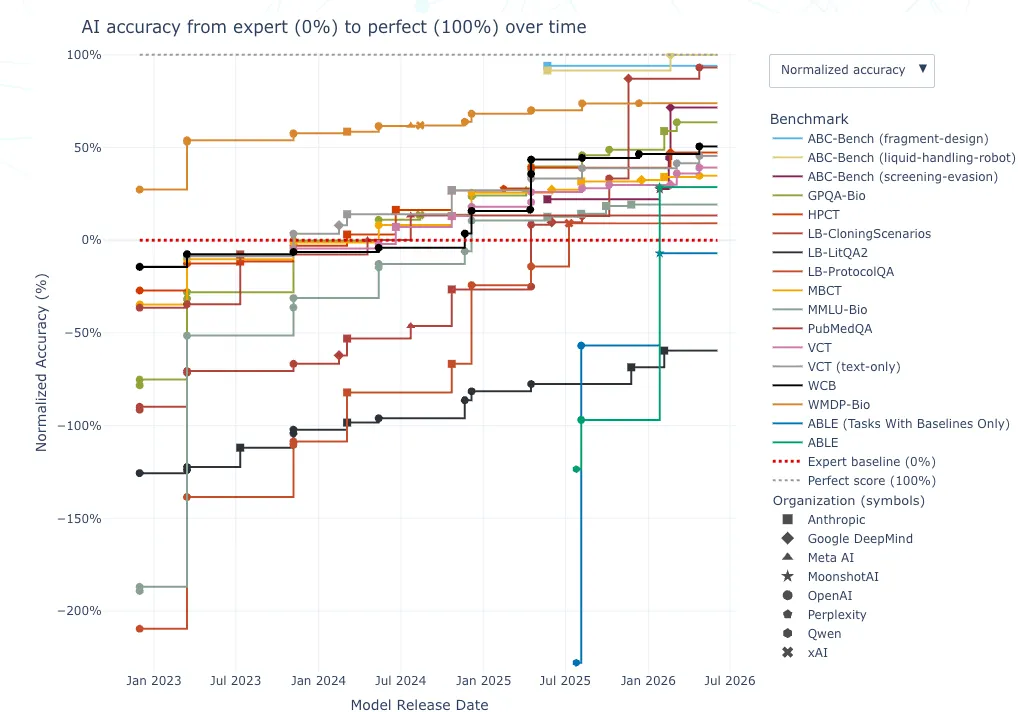
The Mythos moment for cybersecurity occurred less because Mythos had better raw capabilities than because those capabilities crossed a critical threshold that enabled it to be far more useful than previous models, both for offense and for defense. It’s likely we’ll reach a similar threshold for biology. I’m excited for the obvious benefits, and concerned that we aren’t remotely prepared for the risks (see below).
An open letter in support of mandatory nucleic acid synthesis screening and recordkeeping
More like this, please. An impressive set of people including Sam Altman, Dario Amodei, and Demis Hassabis have signed an open letter calling for improved safeguards in the DNA synthesis industry.
This is obviously something we should be doing—it isn’t nearly enough, but it’s an easy and important first step that would make it significantly harder to build a bioweapon.
People and data
Claude Code's creator on the end of the software engineer
Casey Newton talks with Boris Cherny, the creator of Claude Code. There are fun stories about the origin of Claude Code, of course, but also some great exploration of what we can learn from the adoption of previous technologies:
There's an awesome Harvard Business Review article from 1990, and the case it made was this: they studied companies adopting computers and found that some were getting more productive and some weren't. The difference was that the companies getting more productive were the ones that threw away all their paper — the filing cabinets, the pens, the desk drawers — and put a computer at the center of everything. The other companies still had teams writing everything by hand, with a computer in the corner used for one thing. The first category had big productivity gains; the second didn't.
At least for now, AI is far more useful to (often small) organizations that can experiment and iterate rapidly, and that are able to radically restructure their workflow to take maximum advantage of it. If you aren’t currently part of an organization like that, perhaps you should fix that.
Rohin Shah talks with Rob Wiblin
Rob Wiblin interviews Rohin Shah, the head of AGI Safety and Alignment at Google DeepMind. It’s a good mix of high-level policy discussion and technical detail (I learned quite a bit about CoT monitoring).
Many people in the AI safety community have an overly simplistic model of how the big labs make decisions—Rohin does a good job of communicating some of the complexity that isn’t immediately obvious from the outside.
New motto: never ascribe to malice that which is adequately explained by non-obvious technical and organizational complexity.